
Research
Our research is completely based on openly accessible or simulated data sets. It has a rather methodological focus, but always inspired by theoretically important insights from cognitive neuroscience.
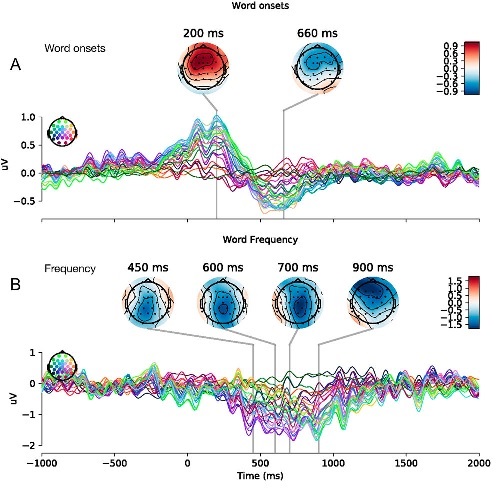
Uncovering neural events in naturalistic tasks with time-resolved multiple regression.
Naturalistic language processing cannot be approached with the analysis methods constructed to handle well-controlled experiments. Language is a multi- and cross-level phenomenon, with sequential interdependencies and correlations between various lexical dimensions. Time-resolved multiple regression allows the analysis of neural time series during natural story comprehension. It consists in modelling continuous brain recordings with multiple regression after embedding linguistic features in a temporal-extension matrix (a distributed-lags model). It identifies neural correlates of linguistic processes, accounting for temporal interdependencies – simultaneously for, e.g. acoustics, phonology and semantics. This has resulted in impactful discoveries about how brains process coherent speech, potentially broadening the class of phenomena that can be studied.
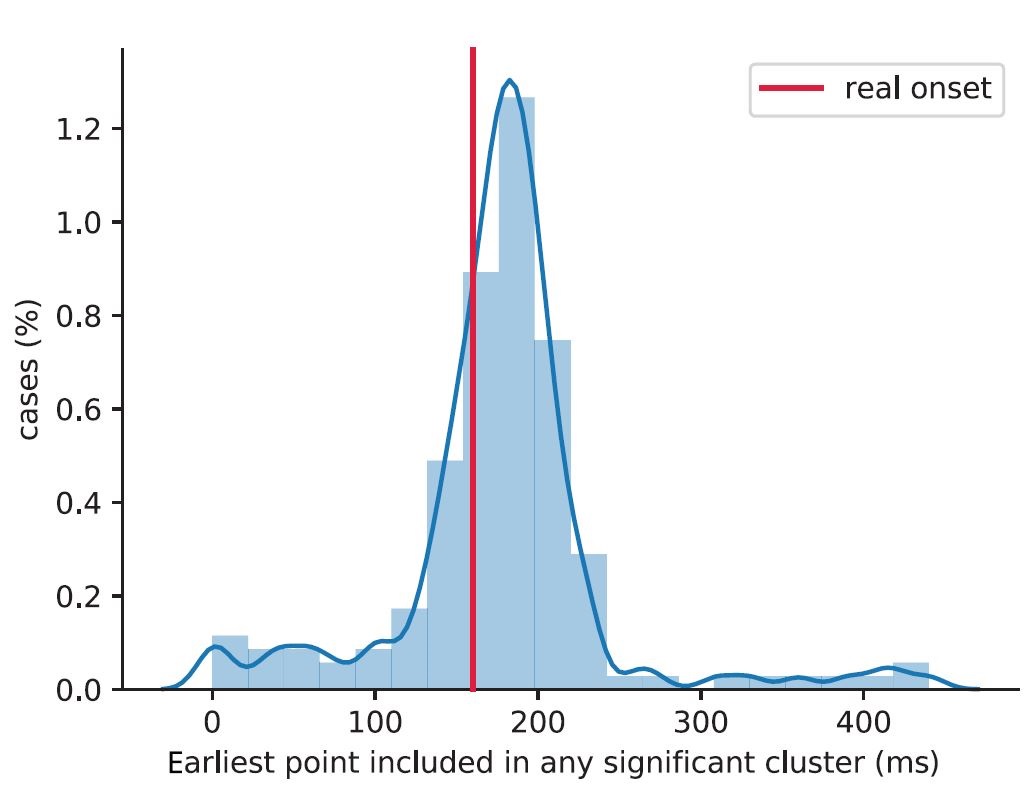
Using cluster-based permutation tests in cognitive neuroscience.
Cluster-based permutation tests are a powerful solution to the multiple comparisons problem in EEG and MEG data. We report on extremely common, yet inapplicable interpretations of this procedure, suggesting unwarranted precision of the actual underlying test statistic and leading to strong, but unsubstantiated claims. We investigate problems and common pitfalls of using and interpreting cluster-based permutation tests. Accurate interpretations of cluster-based permutation tests will contribute to the adequate utilization, as well as the popularity, of this powerful method.